Points lying inside a circle – duplicated point variation
Given three parameters of equal size:
- string S – points names (duplicates allowed)
- int[] X – point coordinate
- int[] Y – point coordinate
Calculate the number of points lying within the circle ranging to the closest duplicated point excluding points crossing the edge of the circle.
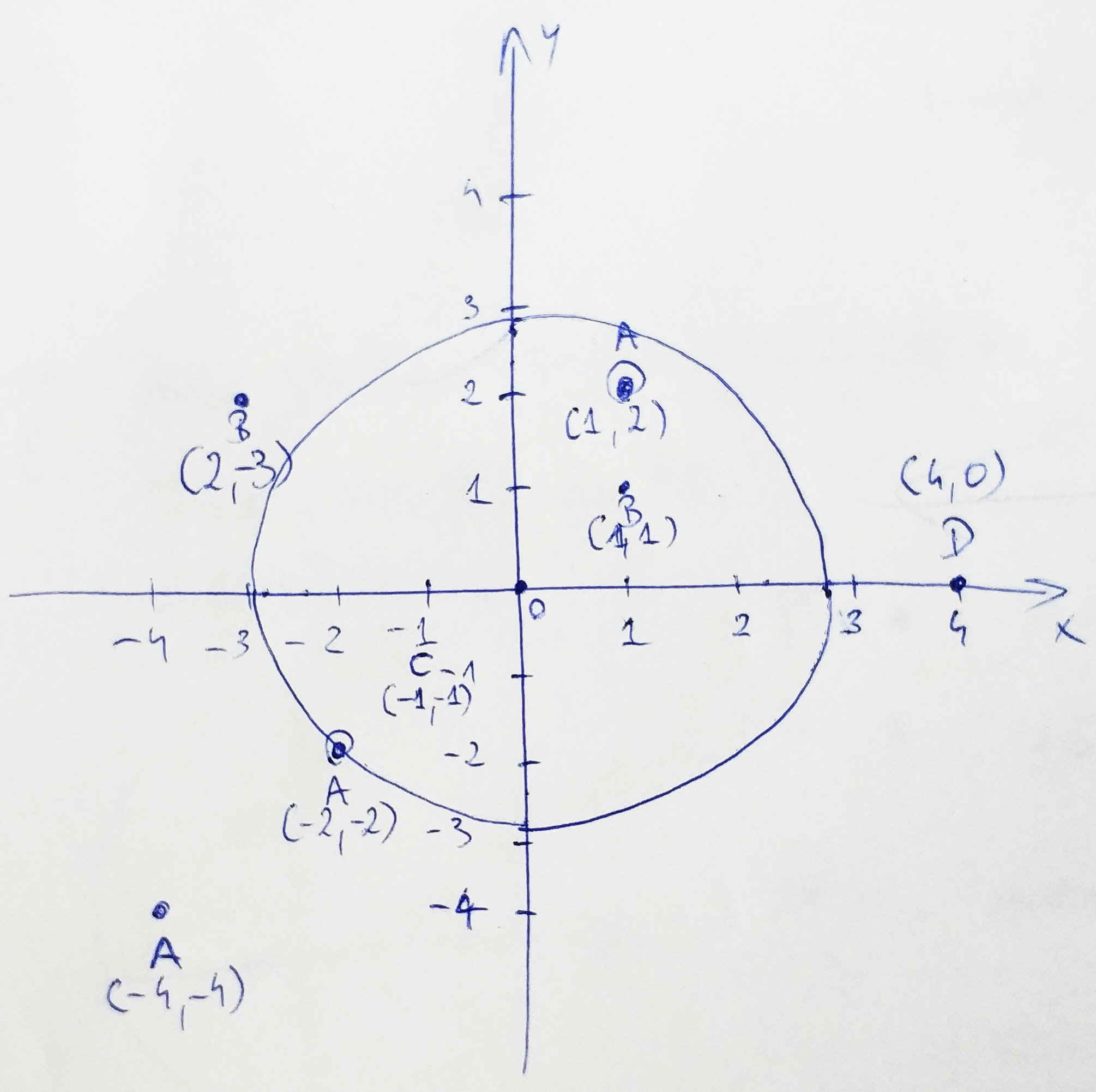
Looking at the chart, the points we are interested in: B (1, 1), A (1, 2) and C (-1,-1). Point A (-2, -2) is excluded because it lies on the circle’s edge. Circle radius is determined upon the closest duplicated point. There are two sets of duplicated points on the above chart: B – ([2, -3], [1,1] and A – ([-2, -2], [1, 2], [-4, -4]).
Solution:
This task is quite easy once you understand that the sign of the coordinates doesn’t matter.
First, let’s start by adding a check if we have any duplicated point groups:
public static int getResult(string S, int[] X, int[] Y)
{
if (S.Distinct().Count() == S.Count())
return 0;
}Secondly, we need to calculate the distance of each point from the center of the plane by using Pythagorean theorem:

Let’s extract it to another method:
private static decimal getPointHypotenuse(int x, int y)
{
return (decimal)Math.Sqrt((Math.Pow(x, 2) + Math.Pow(y, 2)));
}public static int getResult(string S, int[] X, int[] Y)
{
if (S.Distinct().Count() == S.Count())
return 0;
List<Tuple<char, decimal>> list = new List<Tuple<char, decimal>>();
for (int i = 0; i < S.Length; i++)
{
list.Add(new Tuple<char, decimal>(S[i], getPointHypotenuse(X[i], [i])));
}
}Next, since we can have N number of any type of point, let’s group them together in a sorted list:
var aggregated = list.GroupBy(x => x.Item1)
.Where(x => x.Count() > 1)
.Select(g => Tuple.Create(g.Key, g.Min(t => t.Item2)))
.OrderBy(x => x.Item2)
.ToList();The last step is to pick the second lowest number from any of the groups and filter the list of points with their distances to include only points below the limit.
Here’s the full listing:
public static class PointsWithinACircle
{
public static int getResult(string S, int[] X, int[] Y)
{
if (S.Distinct().Count() == S.Count())
return 0;
List<Tuple<char, decimal>> list = new List<Tuple<char, decimal>>();
for (int i = 0; i < S.Length; i++)
{
list.Add(new Tuple<char, decimal>(S[i], getPointHypotenuse(X[i], Y[i])));
}
var aggregated = list.GroupBy(x => x.Item1)
.Where(x => x.Count() > 1)
.Select(g => Tuple.Create(g.Key, g.Min(t => t.Item2)))
.OrderBy(x => x.Item2)
.ToList();
var result = (from s in list
join a in aggregated on s.Item1 equals a.Item1
where s.Item2 > a.Item2
orderby s.Item2
select (s.Item1, s.Item2)).First();
var numberOfPoints = list.Where(x => x.Item2 < result.Item2).Count();
return numberOfPoints;
}
private static decimal getPointHypotenuse(int x, int y)
{
return (decimal)Math.Sqrt((Math.Pow(x, 2) + Math.Pow(y, 2)));
}
}Remote work in the times of COVID-19
Hi fellas! We’re witnessing history and trying to make best out of it. There’s a Chinese saying that you shoudn’t wish to live in the interesting times. Guess we don’t have much chance to decide now.
Anyway, half of the web decided to caught on the wave of the virus and every one seems to be an expert on remote work now. Nevertheless, I’ve spent over 5 years working remotely from places with better or worse conditions for remote work and thought that maybe I’ll also share something you might find useful. Let’s cut the story short and move on to the tips:
1. Clean up your environment
Make it as clean and distractless as possible. If you live with other family members and have a luxury of a separate room, use it. It’s difficult to convince roommates that your’re actually working from home. If you’re trying to solve some important problem, focusing on solution, while being often distracted, things can go sideways very quickly. Firstly, you won’t be productive, and secondly it can cause some frustration and have a negative effect on your domestic partnership.
2. Get dressed
A vision of sipping coffee in pyjamas all day might be exciting, but believe me it isn’t. You’ll be surprised how strong negative effect it might have after a few weeks on you mentally.
3. Schedule your day
It’s important to have a schedule for the day planned as daily and evening routines. Don’t sleep longer than usual, finish your work on time and plan your activities. Even when our range of possibilites is strongly limited during the quarantine, try to manage some time for physical activities and some play. As programmers we have this great possibility to learn something new or polish our skills during this hard time. It will keep you sharp and if everything will go apart and you’ll have to look for a new job, you’re increasing your chances.
4. Prepare for the worst
It’s important to show your employer that you care. It’s a difficult time for every one, so prepare as well as you can. What do I have in mind? Try to acquire simple redundancy in regard to the tools that are necessary for your work. Try to have double internet connection, microphone, headphones, camera, pc/laptop (with VPN configuration and ready for work). Ideally we’d like to have a spare electricity provider, however if we run into problems with the electricity, being not able to git push won’t be our biggest issue… Anyway, we all have to meet the deadlines, so it’s worth to keep the trust between parties and show that they can depend on you.
5. Communicate professionally
When we communicate via text only it’s easy to misinterpretate a message, which can lead to conflicts. It’s also quite easy to forget that the someone, who crashed the build in the pipeline is an actual person, after not seeing some one for a few weeks. Be polite, be cool, be positive. Report your progress on the tasks and also find few moments for a daily coffee maker chit chat.
I guess that’s the crucial picks I wanted to share. Take breaks and appreciate that you’re one of the lucky guys or gals that can work remotely :). Stay positive!

Reordering DataTable Optimization Use Case
Scenario
Let’s assume we have a header based import accepting CSV files, with the following criteria:
- columns can be placed in a file in any order
- any number of columns can be added to an import file
- there can be a variable number of XML columns, which should be translated to a valid XML and placed in a single column matching SQL bulk insert table
- the service should output a DataTable with a schema matching bulk insert table with buckets in XML format
Ok, so we have two types of column:
- simple column, which should be validated and mapped to an existing DB column from a table, to which we’ll be performing a bulk insert
- xml columns, which should be translated to a valid xml and merged into one, because there’s a single xml column in bulk insert table, to which we need to insert
Problem
What’s the problem with this kind of design? First, which comes to my mind is that the xml column in bulk table (it could be json, doesn’t matter) adds verticality to the data storage, which means that sql won’t be able to use simple joins. It also requires parsing the data both ways and, since we don’t know how many xml columns will be included in the import file, it’s difficult to avoid n^2 complexity.
Morever, we get a initial DataTable with a different schema compared to the target DataTable. In the initial DataTable all columns were stored in a string format. We need to fetch the schema and modify the first DataTable.
Expected size of data- 100,000 rows, up to 50 XML columns. In this example I’ll omit the validation part and focus on the reordering service performance.
Initial approach
- We fetched the bulk insert table schema and created a new DataTable object
- For each source table row, a new DataRow was created
- Another for loop iterated through the source rows’ columns
- In the second loop we were checking the correct name of the column and copying value from source table
_destinationDataTable = await _dataSchemaService.GetTemplateSchema(tableName);
for (var row = 0; row < source.Rows.Cast<DataRow>().Count(); row++)
{
var newRow = _destinationDataTable.NewRow();
var xmlBucket = new RateBucketsOverride();
for (var index = 0; index < source.Columns.Count; index++)
{
var cellValue = source.Rows[row].ItemArray[index].ToString();
if (!string.IsNullOrWhiteSpace(cellValue))
{
var columnInfo =
mappedfields.First(c => c.SourceColumn == source.Columns[index].ColumnName);
if (columnInfo.Mapped)
{
var column = GetDataColumn(columnInfo.DbDestinationColumn);
newRow[column] = cellValue;
}
else
{
xmlBucket.BucketOverrides.Add(new BucketOverride
{BucketDescription = columnInfo.SourceColumn, BucketOverrideValue = cellValue});
}
}
}
if (xmlBucket.BucketOverrides.Count > 0) AddBucketsToRow(xmlBucket, newRow);
if (newRow.ItemArray.Length > 0)
_destinationDataTable.Rows.Add(newRow);
}
AddFileName(fileName);Closer look
Ok, the code works and passes all unit tests. What’s wrong with it?
- Whole table coppied every time, row by row, column by column
- Double LINQ string-based column name checking
- OK performance for small to medium number of rows (<5000)
Computional complexity:
(2n+1)*(3*m + 4)=> n*m
Additionally, it turned out during the test that type casting in the outer loop had horrific extreme negative impact on performance.
for (var row = 0; row < source.Rows.Cast<DataRow>().Count(); row++)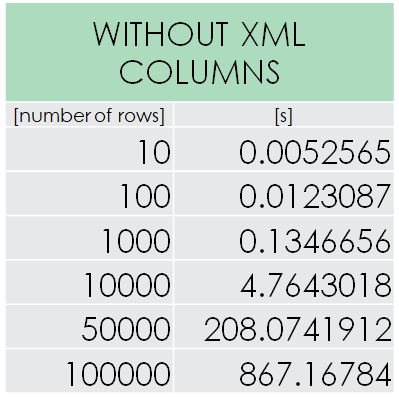 This is the performance of the initial solution. ~14m30s for 100,000 rows is hugely disappoiting and shows how quickly things can go sideways. The duration increase approximately matches expected complexity. Since the whole table is rebuild, it doesn’t matter if there are any XML rows or now. It’s always the worst case scenario. What can we do about it?
This is the performance of the initial solution. ~14m30s for 100,000 rows is hugely disappoiting and shows how quickly things can go sideways. The duration increase approximately matches expected complexity. Since the whole table is rebuild, it doesn’t matter if there are any XML rows or now. It’s always the worst case scenario. What can we do about it?
Using Table Merge
- I added unit tests to check the solution validity
- Performance tests were added to measure the execution time
- Code was refactored into smaller functions for readability
- Instead of creating new table, all operations were performed on a source table, including mapping source columns before iterating through rows.
- Casts were removed from the loops
- Since we can have a n number of XML columns in a file and each bucket can be different, we still iterate over those rows, but only XML columns!
- As a final step, the bulk import table schema is merged into the source table, filling all the missing required columns. It’s quick, since destination table is empty.
if (bucketColumnsPositions.Count > 0)
{
for (var row = 0; row < source.Rows.Count; row++)
{
var xmlBucket = new RateBucketsOverride();
foreach (var idx in bucketColumnsPositions)
{
var cellValue = source.Rows[row].ItemArray[idx].ToString();
if (!string.IsNullOrWhiteSpace(cellValue))
{
xmlBucket.BucketOverrides.Add(
new BucketOverride
{
BucketDescription = source.Columns[idx].ColumnName,
BucketOverrideValue = cellValue
});
}
}
if (xmlBucket.BucketOverrides.Count > 0)
source.Rows[row][_dataSchemaService.ColumnXmlBucket] = ToXml(xmlBucket);
}
}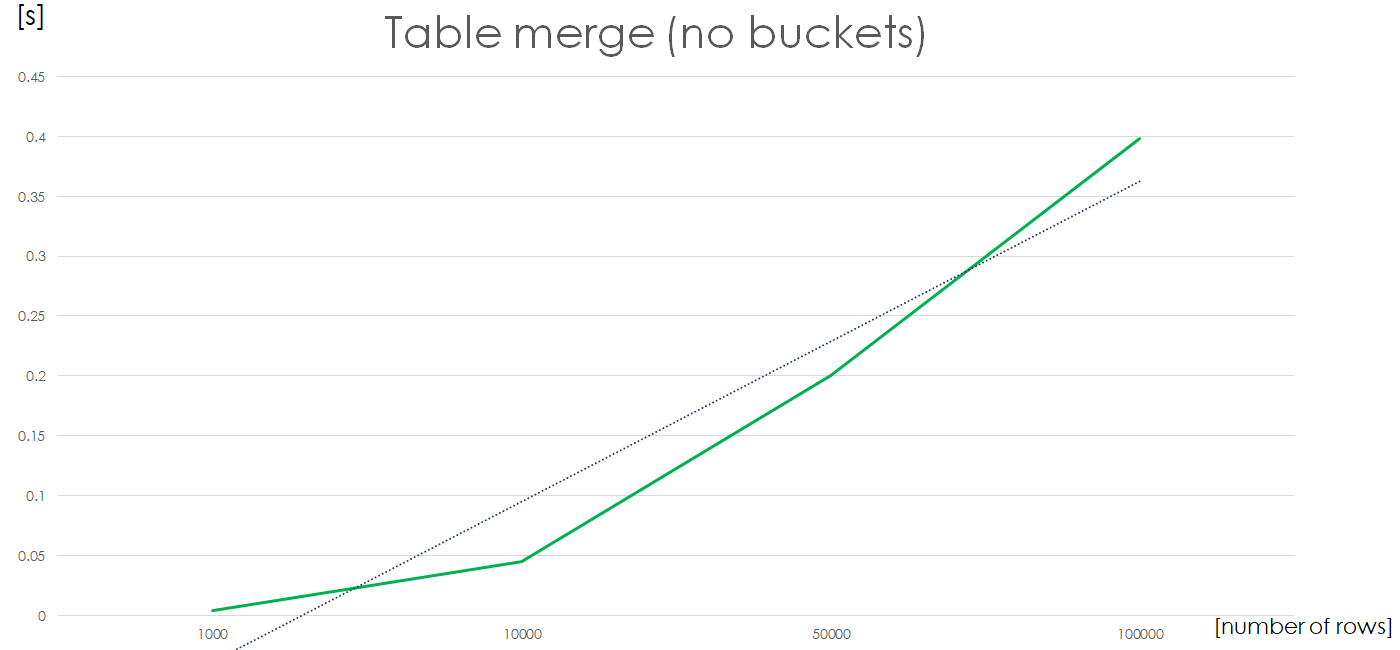
Now the complexity chart looks a lot better. A 2x increase in number of rows in a file results in ~2x increase in calculation time i.e. we have a linear complexity for a file with no XML columns.
Parallel Calculations
Since the number and values of XML columns remain unknown, it’s not possible to further optimize it sequentially as it requires traversing each cell. However, since we are able to link buckets with rest of rows in the DataTable on ID, we can use a parallel calculation.
The issue is that DataTable in C# is thread-safe only for reading, writing to it yields random errors. From the available data structures I picked ConcurrentDictionary as it offers all we need for this task and has a good performance plus offers thread safety.
if (bucketColumnsPositions.Count > 0)
{
Parallel.For(0, source.Rows.Count, (i, row) => {
var xmlBucket = new RateBucketsOverride();
foreach (var idx in bucketColumnsPositions)
{
var cellValue = source.Rows[i].ItemArray[idx].ToString();
if (!string.IsNullOrWhiteSpace(cellValue))
{
xmlBucket.BucketOverrides.Add(
new BucketOverride
{
BucketDescription = source.Columns[idx].ColumnName,
BucketOverrideValue = cellValue
});
}
}
if (xmlBucket.BucketOverrides.Count > 0)
xmlBuckets.TryAdd(i, ToXml(xmlBucket));
});
foreach (var bucket in xmlBuckets)
{
source.Rows[bucket.Key][_dataSchemaService.ColumnXmlBucket] = bucket.Value;
}
}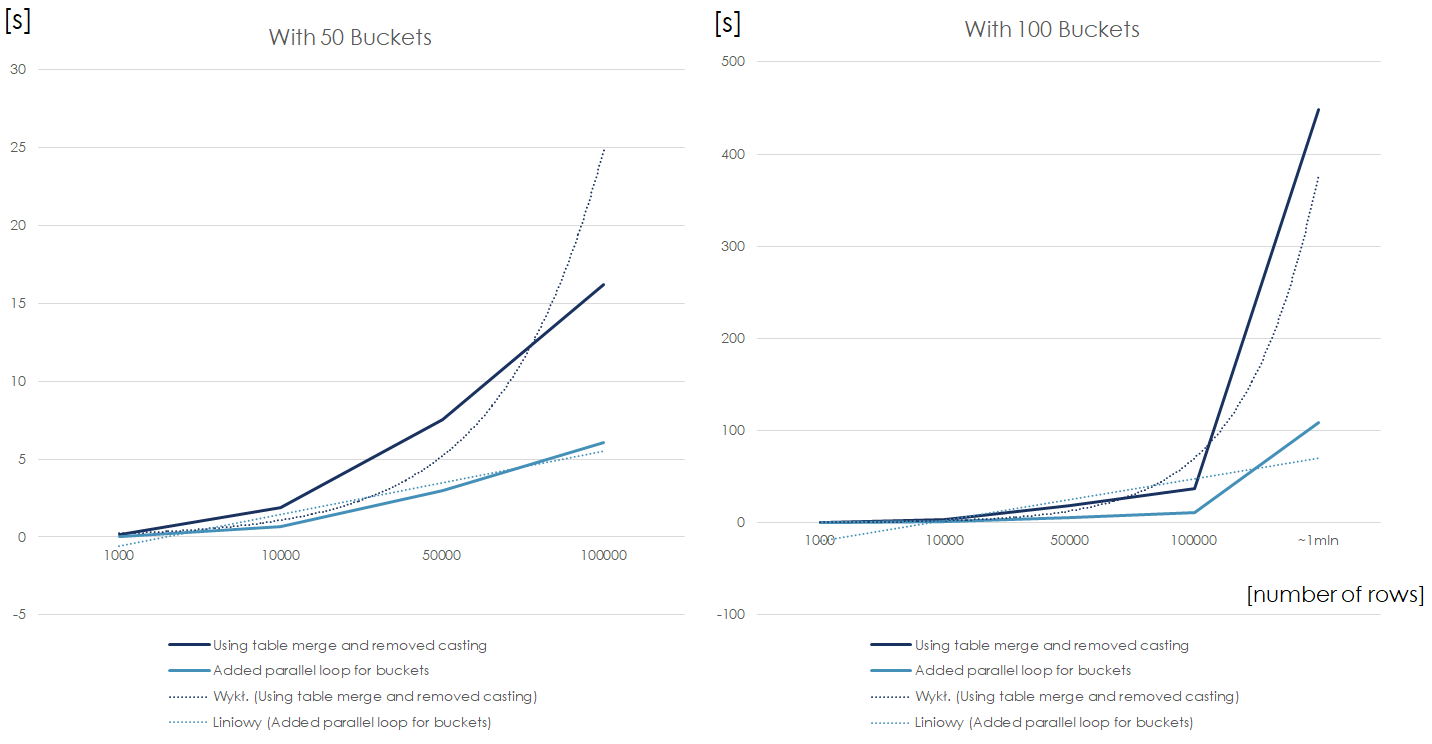
This is a calculation time comparison of the sequential and parallel algorithms using files with 50 and 100 XML columns respectively. We can notice that when the number of rows is drastically higher than number of available threads, the parallel chart breaks the linearity and becomes n (number of rows) * m (number of XML columns above the number of threads).
Thanks to the parallel loops for of XML columns, the growth of calculation time is linear both in terms of number of rows, as well as number of buckets. Precisely, the above is true when number of threads >= number of rows in file, but the reordering service was not a bottleneck anymore.
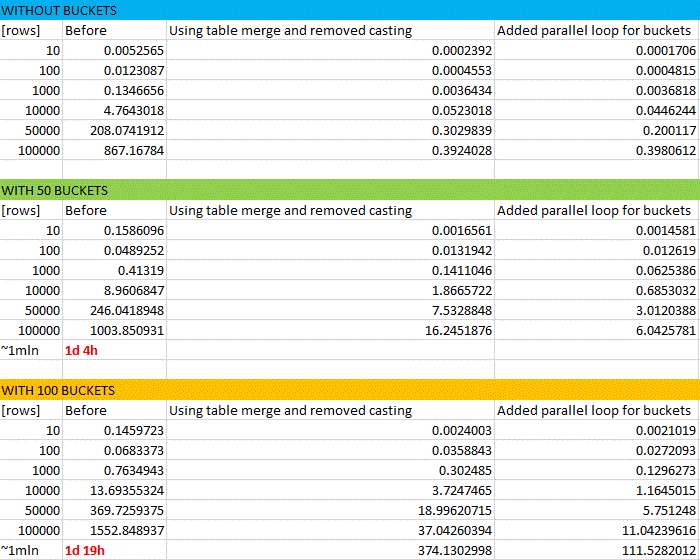
Bonus: here’s the snapshot from real performance tests. The results for 1,000,000 rows were approximated. In a badly written program, it takes almost two days to reorganize 1mln csv rows for an i7 cpu…

Why software fails and buildings don’t
Introduction
Kraków – the city I currently live in seems to be at its cultural and economic bloom. The total office area more than quadrupled during last the 10 years (~400,000 to ~1,750,000 sqm2). You won’t find many spots without a crane toweing on the horizon. I can even see one from my office. One day when we were struggling to make our TeamCity build green again, it made me wonder why software collapses and these buildings don’t.
Orders of magnitude
The last construction disaster happened in Poland in 2003 burying 65 people after the exhibition hall collapsed in Katowice. When considering the number of building raised and maintained over time (~10-15 millions of structures), the reliability of structures exceeds 99.99999% (10^8-9). It’s a no-comparer to the standard build pipeline of any software house or production setup. However, most safety-critical systems can reach that level.
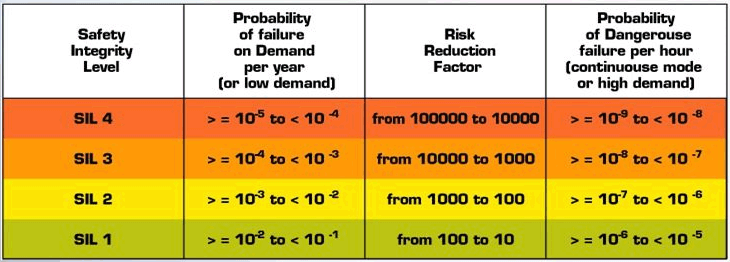
Why is it important? Imagine you’re right answering 99% questions. That’s pretty neat, not many individuals can reach that level. How about 99% fidelity in a record? Some audiophiles might argue about the loss of quality. Now, 99% reliability in the process of developing a NASA space shuttle would result in 25,000 broken parts! Not even Laika – the first hero of the Soviet Space program would board that one.

Overriding vs Shadowing
Hi, in short, I’d like to describe why using method shadowing in a project can be dangerous.
First, let’s have a short introduction to what method overriding and shadowing is.
Overriding – it’s changing the method body. What’s important is that the method signature is resolved at runtime based on the object’s type. The base method has to be declared with ‘virtual’ modifier.
Shadowing – it’s changing the method body. It’s early bound, thus resolved at compile type based on the object’s type. The base method doesn’t have to have any special modifier. However, in the derived class, the shadowing method can optionally include ‘new’ modifier (it’s not necessary, but without it compilers generate a warning).

How to Create a Mind – Ray Kurzweil
The Structure
“How to Create a Mind” is the latest nonfiction book by Ray Kurzweil as of today. It starts technical and shifts toward the philosophical aspect of a mind. After a brief introduction to the nature of thinking, the author moves to use cases of the Markov model in the speech recognition systems based on Siri and IBM’s Watson examples. Kurzweil also elaborates on the history of computing from the very first algorithms from the 18-th century, through Turing machine and the works of John von Neumann, which laid the foundations for the current machines. Few next chapters touch are dedicated to neocortex part of the human brain and the ability to reproduce the pattern-recognition ability in a digital form. The remaining part is purely philosophical but in a good way.
The Essence
It’s the mind. Observed from different angles. Most of the examples included in this book are stimulating, such as the experiments with split-brain patients and the reasoning about a false cause. In short, split-brain is a syndrome in which the two cerebral hemispheres get disconnected. It turns out that even though the hemispheres cannot communicate with each other, which means that patients live with two separate brains, subjects may function normally. However, since the hemispheres are cross-connected (left hemisphere is connected to the right part of the body and vice-versa), limiting brain inputs to one of the hemispheres bring some unexpected results.
The left hemisphere in a split-brain patient usually sees the right visual field, and vice versa. Gazzaniga and his colleagues showed a splitbrain
patient a picture of a chicken claw to the right visual field (which was seen by his left hemisphere) and a snowy scene to the left visual field
(which was seen by his right hemisphere). He then showed a collection of pictures so that both hemispheres could see them. He asked the patient
to choose one of the pictures that went well with the first picture. The patient’s left hand (controlled by his right hemisphere) pointed to a picture of a shovel, whereas his right hand pointed to a picture of a chicken. So far so good—the two hemispheres were acting independently and sensibly.
“Why did you choose that?” Gazzaniga asked the patient, who answered verbally (controlled by his left-hemisphere speech center), “The chicken
claw obviously goes with the chicken.” But then the patient looked down and, noticing his left hand pointing to the shovel, immediately explained this (again with his left-hemisphere-controlled speech center) as “and you need a shovel to clean out the chicken shed.”This is a confabulation. The right hemisphere (which controls the left arm and hand) correctly points to the shovel, but because the left
How to Create a Mind – Ray Kurzweil
hemisphere (which controls the verbal answer) is unaware of the snow, it confabulates an explanation, yet is not aware that it is confabulating. It is
taking responsibility for an action it had never decided on and never took, but thinks that it did.
Ray also discusses the quirks of free will and the problem of determining how to “proof” consciousness. In numerous experiments (the most famous is the Libet one), when the research group had to make a simple decision such as whether they’ll like to have a coffee. It turns out that the motoric part of the brain raises activity even half a second earlier before the decision-making area of the brain gets stimulated. This means that the body is already preparing the movement for grabbing the coffee before the aware decision is made, thus implying our free will is limited and we act as complicated state machines, not fully aware of the reasons behind our actions.
I find the consciousness theory part the most interesting. Kurzweil briefly describes the two consciousness theory by David Chalmers.
Chalmers does not attempt to answer the hard question but does provide some possibilities. One is a form of dualism in which consciousness
per se does not exist in the physical world but rather as a separate ontological reality. According to this formulation, what a person does is basedon the processes in her brain. Because the brain is causally closed, we can fully explain a person’s actions, including her thoughts, through itsprocesses. Consciousness then exists essentially in another realm, or at least is a property separate from the physical world. This explanation doesnot permit the mind (that is to say, the conscious property associated with the brain) to causally affect the brain.
Another possibility that Chalmers entertains, which is not logically distinct from his notion of dualism, and is often called panprotopsychism, holds that all physical systems are conscious, albeit a human is more conscious than, say, a light switch.
I tend to agree with the second theory that everything is conscious ‘to its own measure’, however, most of the subjects are simple. A light switch is ‘conscious’ of its two states (on/off). An ant is conscious of its closest surrounding, able to move based on inputs that come to its brain and perform logical operations such as to eat, to fight or to run (ant example is even more interesting by the fact for it seems a hive of ants is more intelligent and ‘aware’ than a single representative). A fish then is more conscious than an ant because of the more advanced decision-making system and event more inputs that it can accept and process at a given time. Then we move to mammals such as dogs, which have dreams, can solve simple logic problems, have more diverse and even more advanced brain. However, most experiments proof that dogs are unaware of their reflection. Well, human beings until the age of 2 can do neither, however, we learn that by observing a mirror and using our cause-and-effect system to link our movements with the reflection movements and eureka! comprehend our own reflection. Interestingly, chimpanzees, having a brain which almost resembles ours, can do that too.
We usually think of insects as mechanical constructs, by virtue of the rather simple and transparent logic they follow. Yet while rejecting consciousness of dogs or chimpanzees, we find some of the human traits in them, because we tend to interpret their actions by wrapping them with human intentions. However, if there was a machine or an organism 100 times more intelligent than humans, what would it think of us? Driven by desires, fears, hunger etc. which all stem from chemical reactions. Vessels armed with really complex (from a human perspective) processor, pattern-recognizer and uncertainty-based decision-making system? Wouldn’t it find our actions semi-automatical? If we were able to completely disassemble the brain, tracking each signal bit by bit, wouldn’t we found ourselves just the executors of some greater, reversed entropy, which drives spiders to weave their nets?
Summary
Overall, the book is a great brain teaser, however, one thing I find unnecessary is the chapter containing riposte for the critics of Kurzweil works. I may only wonder why Kurzweil decided to include those in this book. Nevertheless, I appreciate the world blooming with writings like this one.

Summa Technologiae – Stanisław Lem
It’s 1964, one of the greatest Polish science-fiction writers and futurologists is about to finish his latest book called “Summa Technologiae”. The name refers to the “Summa Theologiae” by Thomas Aquinas, which in the 13th century was the compendium of all the main theological teachings. It summed up the current state of knowledge. Similarly, in the middle of 1960s Lem sets off to a meta-journey to recon the world of technology, armed only with his intellect bounded by the restrictions of the Iron Curtain.
To approach this book without consideration of its historical and geopolitical background would be inappropriate. Moreover, hardly could we appreciate the charm of the writer, who, 26 years before the Internet became public, foresaw that for people to become a singular intelligent organism they would need “some kind of telephone” for sharing information globally…
Largest region in the matrix – DFS & BFS
If you have or had troubles understanding breath or depth first search, you’ve come to the right place. Here it is – recursive graph search made easy.
Depth-First Search
Depth-first search (DFS) is a method for exploring a graph. In a DFS, you follow the child of traversing node, meaning if the current node has a child, with each step you’ll go deeper into the graph in terms of distance from the root. If a node hasn’t any unvisited children, then go up one level to parent.
Breadth-First Search
Breadth-first search (BFS) is a method for exploring a graph. In a BFS, you first explore all the nodes one step away from the root, then all the nodes two steps away, etc.
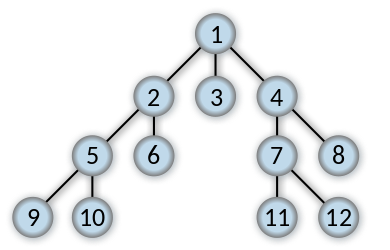
The Problem
Consider a matrix with rows and columns, where each cell contains either a ‘0’ or a ‘1’ and any cell containing a 1 is called a filled cell. Two cells are said to be connected if they are adjacent to each other horizontally, vertically, or diagonally. If one or more filled cells are also connected, they form a region. find the length of the largest region.
Input : M[][5] = { 0 0 1 1 0
1 0 1 1 0
0 1 0 0 0
0 0 0 0 1 }
Output : 6
Ex: in the following example, there are 2 regions one with length 1 and the other as 6.
The largest region : 6Code Complete – Steve McConnell
In this short review, I’ll try to distill key features of this over 900 pages book.
Simply speaking, if the Clean Code by G. Martin is the “what”, this book is the “how” of programming practices. It covers key areas of daily programming tasks from problem definition, through planning, software architecture, debugging, unit testing, naming to integration and maintenance.
70-483 Notes
A while ago I passed the 70-483 exam and thought I might share some of my notes, which I think are the most takeaways from the learning material. The exam itself was fair, but as almost every knowledge test it had some very specific questions such as name of the methods on interfaces (e.g. CompareTo vs Compare on IComparable and IComparer respectively).
1. Parallel LINQ queries does not guarantee preserved order, need to add the AsOrdered() characteristic. It might be quicker than sequential linq query, but it’s not deterministic, need to be tested. Example PLINQ queries:
var orderedCities2 = (from city in cities.AsParallel().AsOrdered()
where city.Population > 10000
select city)
.Take(1000);
var plinqQuery = table
.AsParallel()
.Where(n => Enumerable.Range(2, (int) Math.Sqrt(n.Item1)).All(i => n.Item1 % i > 0))
.Take(10)
.ToList();