Introduction
Kraków – the city I currently live in seems to be at its cultural and economic bloom. The total office area more than quadrupled during last the 10 years (~400,000 to ~1,750,000 sqm2). You won’t find many spots without a crane toweing on the horizon. I can even see one from my office. One day when we were struggling to make our TeamCity build green again, it made me wonder why software collapses and these buildings don’t.
Orders of magnitude
The last construction disaster happened in Poland in 2003 burying 65 people after the exhibition hall collapsed in Katowice. When considering the number of building raised and maintained over time (~10-15 millions of structures), the reliability of structures exceeds 99.99999% (10^8-9). It’s a no-comparer to the standard build pipeline of any software house or production setup. However, most safety-critical systems can reach that level.
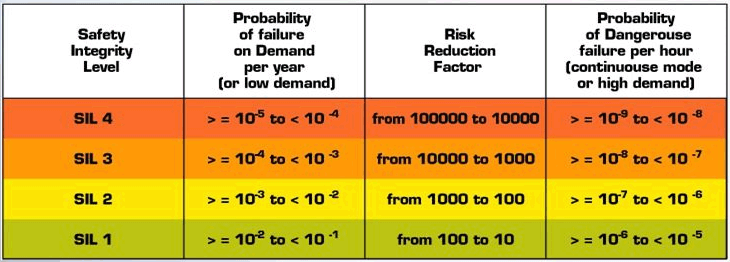
Why is it important? Imagine you’re right answering 99% questions. That’s pretty neat, not many individuals can reach that level. How about 99% fidelity in a record? Some audiophiles might argue about the loss of quality. Now, 99% reliability in the process of developing a NASA space shuttle would result in 25,000 broken parts! Not even Laika – the first hero of the Soviet Space program would board that one.

Standardization
One of the key features of the engineering that allows whole industries to shift toward make-to-order production type is the dominant standardization. These out-of-the-box solutions are documented, simulated, then carefully designed and… rigid. Let’s have a look at the carmakers. Toyota, while being a huge concern, offers only several internal combustion engines. Each of the prototypes, before going into mass production, goes through a series of tests, including endurance (millions of kilometers in total) plus so-called hot and cold tests.
Meanwhile, many software projects are custom-tailored or even written from scratch. Open source projects became our building blocks and, ironically, that’s the most reliable part we’ve got. A custom solution can’t be tested at a level of standardized one, because of the very different scale of usage as well as time and budget constraints of the running project. Less standardization translates to limited room for thorough elements testing.
Heuristics
Thousands of years of experience is not the only aspect differentiating architecture physics from software development. The main fact, which distinguishes engineering from software development is the actual science.
There are exact formulas for calculating transverse, torsional or axial loading accompanied by reference tables for various materials. We can calculate and simulate physical systems behavior under stress and, after adding a margin of safety, design a reliable solution.
On the contrary, software development is in its infancy. Yet most of us tend to think we move along the edge of technology, stomping on a solid ground. But are we? Let’s face some basic questions: why exactly classes should have single responsibility? what does it mean for a variable to have a good name if people from different cultures use different semantics? what are the critical points of architecture? what is the formula for calculating system reliability? Can we come up with an equation for any of these? Let’s take the pink glasses off – besides hardware related physics, set, type, computation and few other theories, in the process of software development we use nothing but heuristics.
Project management
Since the birth of agile manifesto in 2001 scrum methodology conquered the IT world. Incremental deliveries reduced feedback cycle time, allowing teams to build trust with investors while staying close to a dynamically changing requirements. However, scrum methodology is the opposite of how engineering projects are run. A bridge is opened when it’s done, no matter how big is the client pressure to open the road. The projects of such size are never canceled when they exceed the deadline. Morever, their requirements won’t change during the building process. After the design phase is done, it’s done. No changes are accepted without going through the whole cycle once again. The project is firm.
Software vs hardware engineering: Why Scrum is not compatible?
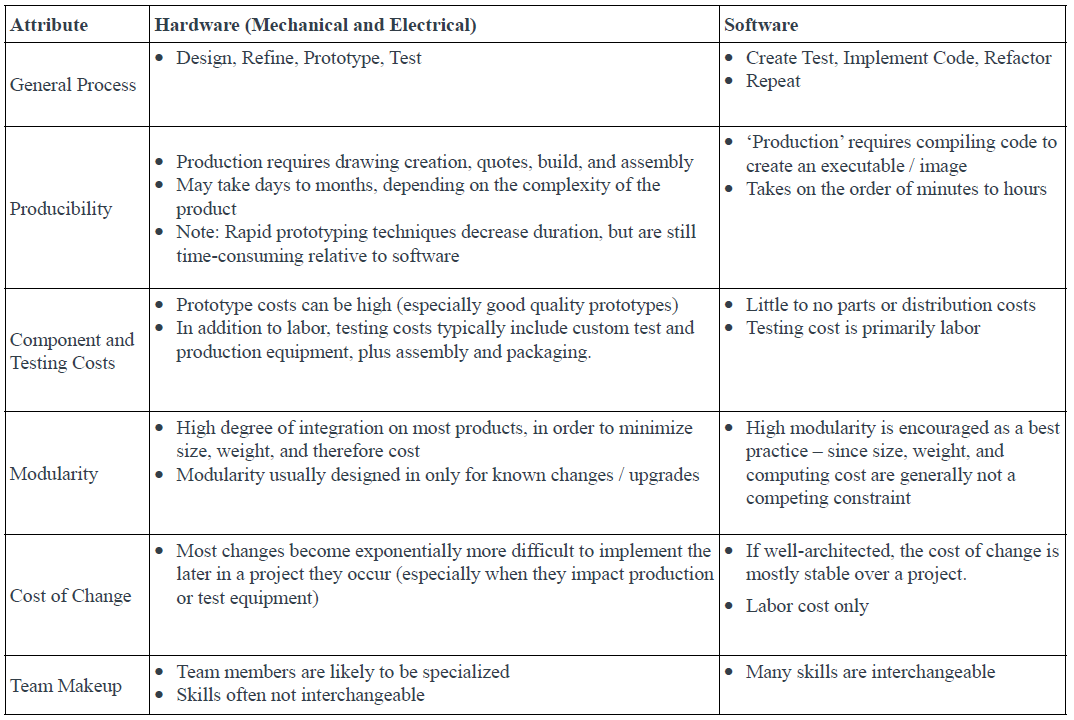
Meanwhile, the time to market for the developers’ solution is shorter than in engineering. We are expected to adjust to everchanging requirements. To build on a fluid architecture and infrastructure, often remaining a grey area until the very end of the project. Of course, it has lots of advantages and we have to keep in mind that developing a web service is not a safety-critical function. However, an increase in the speed of development inevitably impacts the rate of errors.
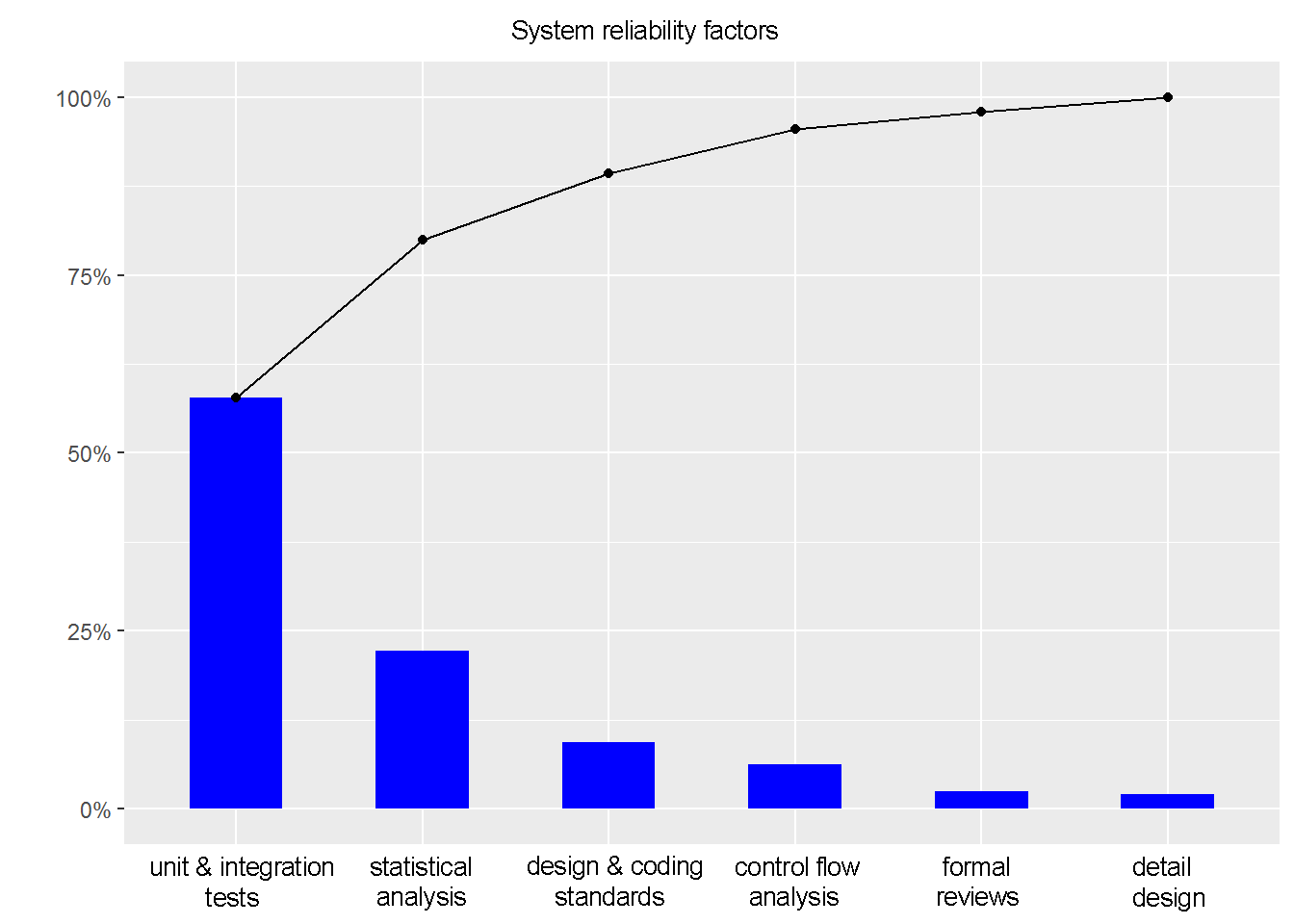
Let’s have a look at an overview Pareto chart of system reliability factors. As with other Pareto charts, we can notice that it’s quite easy to reach ~96-98% effectiveness, however, reaching the 99%+ reliability requires a lot of resources (please note that simplified version of this chart doesn’t include all factors). Data studies show in safety-critical systems the cost of developing a solution is statistically 5-20 times higher compared to a regular project. After all, It’s ok for most of e.g. WebAPI projects to be just ‘good enough’.
Safety-critical
There were several quite spectacular software failures in history, just to mention a few:
Patriot missile
During the Gulf War, twenty-eight U.S. soldiers were killed and almost one hundred others were wounded when a nearby Patriot missile defense system failed to properly track a Scud missile launched from Iraq. The cause of the failure was later found to be a programming error in the computer embedded in the Patriot’s weapons control system.
The problem was that the calculation used not precise enough representation of time, which in a long-running process caused a delay in time, causing the anti-missile system to fire too late. This accident let to 28 people killed.
You can read more detailed analysis here.
Therac-25
The Therac-25 was a computer-controlled radiation therapy machine produced by AECL in the 80s, which offered a revolutionary dual treatment mode. It was also designed from the outset to use software-based safety systems rather than hardware controls.
The six documented accidents occurred when the high-current electron beam generated in X-ray mode was delivered directly to patients. Two software faults were to blame. One, when the operator incorrectly selected X-ray mode before quickly changing to electron mode, which allowed the electron beam to be set for X-ray mode without the X-ray target being in place. A second fault allowed the electron beam to activate during field-light mode, during which no beam scanner was active or target was in place.
Previous models had hardware interlocks to prevent such faults, but the Therac-25 had removed them, depending instead on software checks for safety.
The post-failure analysis pointed out that a single developer was responsible for the entire module, without any code review or external audit. Moreover, there was no documentation, no kill switches, and no integration tests. The first device was assembled in a hospital and the company responsible for Therac-25 ignored users’ feedback after the first victim, trying to push the responsibility to incorrect setup.
Ariane-5
Ariane 5 is a European heavy-lift launch vehicle that is part of the Ariane rocket family, an expendable launch system designed by the French government space agency Centre national d’études spatiales (CNES).
On June 4, 1996 an unmanned Ariane 5 rocket launched by the European Space Agency exploded just forty seconds after its lift-off from Kourou, French Guiana. The rocket was on its first voyage, after a decade of development costing $7 billion. The destroyed rocket and its cargo were valued at $500 million. A board of inquiry investigated the causes of the explosion and in two weeks issued a report. It turned out that the cause of the failure was a software error in the inertial reference system. Specifically a 64 bit floating point number relating to the horizontal velocity of the rocket concerning the platform was converted to a 16 bit signed integer. The number was larger than 32,767, the largest integer storable in a 16 bit signed integer, and thus the conversion failed.
The module had a backup, which shared the same codebase, thus giving up to the same bug even before the main system failure.
You can read more about the story here.
Aftermath
The question remains: can a reliable software be built after all? Let’s explicitly define the reliability to the order of magnitude of engineering projects – 10^9h mean time between failures. It turns out it’s not only possible but such software exists: safety and mission-critical. The difference between those two is, simply speaking, safety-critical system is the one of which failure may cause death, pollution or other threat to the environment (x-ray tube driver). The mission-critical system is an essential element in fulfiling its objective (planetary rover operating system). Many systems are both (airplane autopilot).
How is it done? Let’s have a look at the NASA System Engineering handbook. The key differences in the development process compared to an ordinary software project are:
- Detailed design
- Formal review of detailed design
- Running full documentation
- Formal code reviews by minimum of two peers
- Formal detailed design documents
- Formal code external inspections
- Static analysis
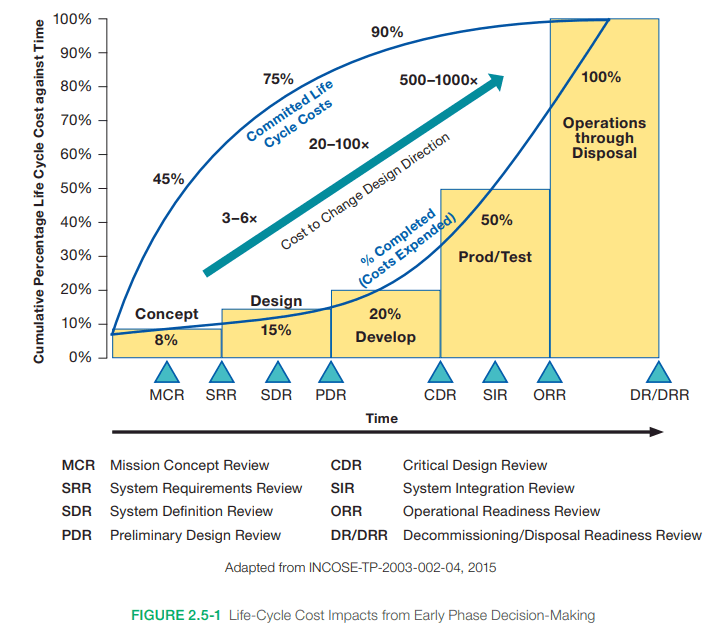
The implementation of safety-critical systems is 10 times more expensive on average. The distribution ranges from 5-20. An interesting fact though is that the difference is strongly negatively correlated with the developers experience. In other words, the more knowledgeable developers are the smaller the development rate difference between non-safety and safety-critical systems, expressed with lines of codes per hour.
Software development process characteristics
Let’s have a look at the software development process itself.
Testing
Test-driven development has been around for some time already. I acknowledge it advantages, however usually I take more old-fashioned approach – write function code first then focus on testing. However, there’s one important advantage of TDD. When starting from tests, you can look at the problem in more abstract way. Focus on constraints and requirements plus compose classes bearing in mind their testability. It also helps to avoid the private functions code smell: if a service has a lot of private functions, it usually means those should be delegated to some other subsystem.
There’s another problem with testing though. In most cases, the same person is responsible for the development and tests, so if someone doesn’t think of any failure scenario during the development, there’s a low chance he/she will think of it when writing test cases. It’s difficult to spot our own mistakes, just as it is in case of text proofreading, because in the process we follow the same neural pathways.
Architecture
,,As a strictly designed grammar, the system allows free, playful application.”
Otl Aicher
Modern agile methodologies tend to overcome the need for detail design and it’s difficult not to agree with the reasons behind it. However, I cannot underline enough the importance of solid architecture. No architecture is bad architecture.
,,Art lives from constraints and dies from freedom.”
Leonardo Da Vinci
Only after the system boundaries are defined the developers can move freely in a project making confident decisions. Without transparent architecture, devs need to discuss every decision made or the codebase will quickly become clutter.
,,The more constraints one imposes, the more one frees one’s self.”
Igor Stravinsky
Bull in a china shop
Ok, this is one is going to be controversial ;). The software community manages to define safety standards for the most common attacks of web applications such as XSS scripting and SQL injections. While most open-sourced and commercial solutions seem to be secure against those trivial intrusions, more sophisticated techniques still lead to discovering 0-day vulnerabilities. However, there’s one major difference between the real world structures and software programs i.e. legal liability for tampering with it. When looking at carmakers, you also lose all guarantees after modification of car engine (such as chip tuning a new turbocharged car) or any other system.
Can you imagine the consequences of someone approaching a city bridge and cutting off one of the arch ties just to see what happens? Or if anyone tore down the load-bearing wall of some public or private building to stress test it? It’s a serious offense. Why then do we allow users to submit dangerous scripts and try to steal or erase a database? Whole responsibility is put on the ones who made the system. One of the first attempts to cover that area was the Computer Misuse Act issued in 1990, in which hacking attempts got formalized.
Uncle Bob often states the need of imposing formal restrictions on the software development industry, which he foresees is going to be triggered by a big enough disaster caused by a software bug. However, maybe we should also hold users accountable for improper software usage?
Collapsing software
I’ve been doing this for thirty-six years. I’ve read hundreds of accident reports and many of them have software in them. And every someone that software was related, it was a requirements problem. It was not a coding problem. So that’s the first really important thing. Everybody’s working on coding and testing and they’re not working on the requirements, which is the problem.
Dr Nancy Leveson
It’s not only rotting or technical debt that affects software and turns it from a knight in a shiny armor into a confused zombie. It’s also the change of the infrastructure and the external components on which the project is dependent that may affect product stability. In a world of tangible engineering basic assumptions don’t change after a building is finished, but in software development you can never be sure.
I recommend having a full read by Kristian Hansen.
Summary
Great, time to sum up. Firstly, please pardon the provoking title. Buildings, bridges, engines, they all fail sometimes. So relax, it’s possible to build as reliable software as the engineering, products just mentioned – it’s just not always worth it. Most of our solutions are not safety-critical systems, therefore we need to find the balance between the ability to deliver quickly, built modular, testable solution and to satisfy both time and budget constraints.
Below you’ll find a list of recommended techniques that bring the most value to the most reliable software system on Earth (and probably even in the outer space).
Checklist
- unit & integration tests
- delegating writing tests to different developer than the one responsible for the feature
- code review (2 person ideally)
- static analysis (more about the value it can bring here)
- clean architecture
- agreeing on coding standard / conventions
- avoiding recursion

R – recommended, HR – highly recommended, M – must
