Reordering DataTable Optimization Use Case
Scenario
Let’s assume we have a header based import accepting CSV files, with the following criteria:
- columns can be placed in a file in any order
- any number of columns can be added to an import file
- there can be a variable number of XML columns, which should be translated to a valid XML and placed in a single column matching SQL bulk insert table
- the service should output a DataTable with a schema matching bulk insert table with buckets in XML format
Ok, so we have two types of column:
- simple column, which should be validated and mapped to an existing DB column from a table, to which we’ll be performing a bulk insert
- xml columns, which should be translated to a valid xml and merged into one, because there’s a single xml column in bulk insert table, to which we need to insert
Problem
What’s the problem with this kind of design? First, which comes to my mind is that the xml column in bulk table (it could be json, doesn’t matter) adds verticality to the data storage, which means that sql won’t be able to use simple joins. It also requires parsing the data both ways and, since we don’t know how many xml columns will be included in the import file, it’s difficult to avoid n^2 complexity.
Morever, we get a initial DataTable with a different schema compared to the target DataTable. In the initial DataTable all columns were stored in a string format. We need to fetch the schema and modify the first DataTable.
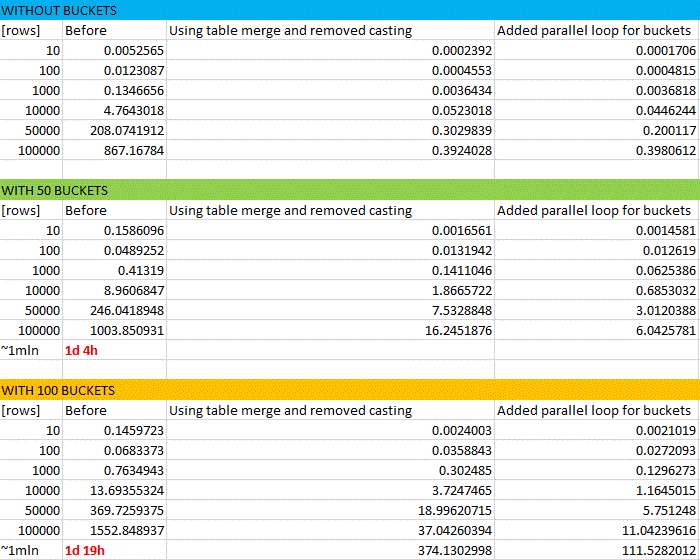
Expected size of data- 100,000 rows, up to 50 XML columns. In this example I’ll omit the validation part and focus on the reordering service performance.
Initial approach
- We fetched the bulk insert table schema and created a new DataTable object
- For each source table row, a new DataRow was created
- Another for loop iterated through the source rows’ columns
- In the second loop we were checking the correct name of the column and copying value from source table
_destinationDataTable = await _dataSchemaService.GetTemplateSchema(tableName);
for (var row = 0; row < source.Rows.Cast<DataRow>().Count(); row++)
{
var newRow = _destinationDataTable.NewRow();
var xmlBucket = new RateBucketsOverride();
for (var index = 0; index < source.Columns.Count; index++)
{
var cellValue = source.Rows[row].ItemArray[index].ToString();
if (!string.IsNullOrWhiteSpace(cellValue))
{
var columnInfo =
mappedfields.First(c => c.SourceColumn == source.Columns[index].ColumnName);
if (columnInfo.Mapped)
{
var column = GetDataColumn(columnInfo.DbDestinationColumn);
newRow[column] = cellValue;
}
else
{
xmlBucket.BucketOverrides.Add(new BucketOverride
{BucketDescription = columnInfo.SourceColumn, BucketOverrideValue = cellValue});
}
}
}
if (xmlBucket.BucketOverrides.Count > 0) AddBucketsToRow(xmlBucket, newRow);
if (newRow.ItemArray.Length > 0)
_destinationDataTable.Rows.Add(newRow);
}
AddFileName(fileName);Closer look
Ok, the code works and passes all unit tests. What’s wrong with it?
- Whole table coppied every time, row by row, column by column
- Double LINQ string-based column name checking
- OK performance for small to medium number of rows (<5000)
Computional complexity:
(2n+1)*(3*m + 4)=> n*m
Additionally, it turned out during the test that type casting in the outer loop had horrific extreme negative impact on performance.
for (var row = 0; row < source.Rows.Cast<DataRow>().Count(); row++)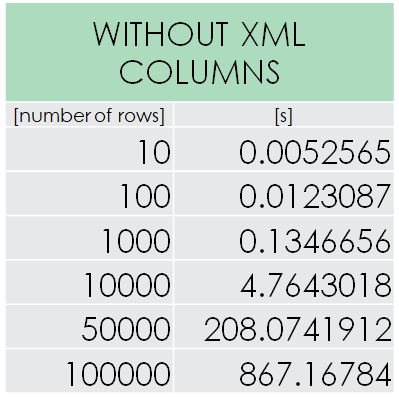 This is the performance of the initial solution. ~14m30s for 100,000 rows is hugely disappoiting and shows how quickly things can go sideways. The duration increase approximately matches expected complexity. Since the whole table is rebuild, it doesn’t matter if there are any XML rows or now. It’s always the worst case scenario. What can we do about it?
This is the performance of the initial solution. ~14m30s for 100,000 rows is hugely disappoiting and shows how quickly things can go sideways. The duration increase approximately matches expected complexity. Since the whole table is rebuild, it doesn’t matter if there are any XML rows or now. It’s always the worst case scenario. What can we do about it?
Using Table Merge
- I added unit tests to check the solution validity
- Performance tests were added to measure the execution time
- Code was refactored into smaller functions for readability
- Instead of creating new table, all operations were performed on a source table, including mapping source columns before iterating through rows.
- Casts were removed from the loops
- Since we can have a n number of XML columns in a file and each bucket can be different, we still iterate over those rows, but only XML columns!
- As a final step, the bulk import table schema is merged into the source table, filling all the missing required columns. It’s quick, since destination table is empty.
if (bucketColumnsPositions.Count > 0)
{
for (var row = 0; row < source.Rows.Count; row++)
{
var xmlBucket = new RateBucketsOverride();
foreach (var idx in bucketColumnsPositions)
{
var cellValue = source.Rows[row].ItemArray[idx].ToString();
if (!string.IsNullOrWhiteSpace(cellValue))
{
xmlBucket.BucketOverrides.Add(
new BucketOverride
{
BucketDescription = source.Columns[idx].ColumnName,
BucketOverrideValue = cellValue
});
}
}
if (xmlBucket.BucketOverrides.Count > 0)
source.Rows[row][_dataSchemaService.ColumnXmlBucket] = ToXml(xmlBucket);
}
}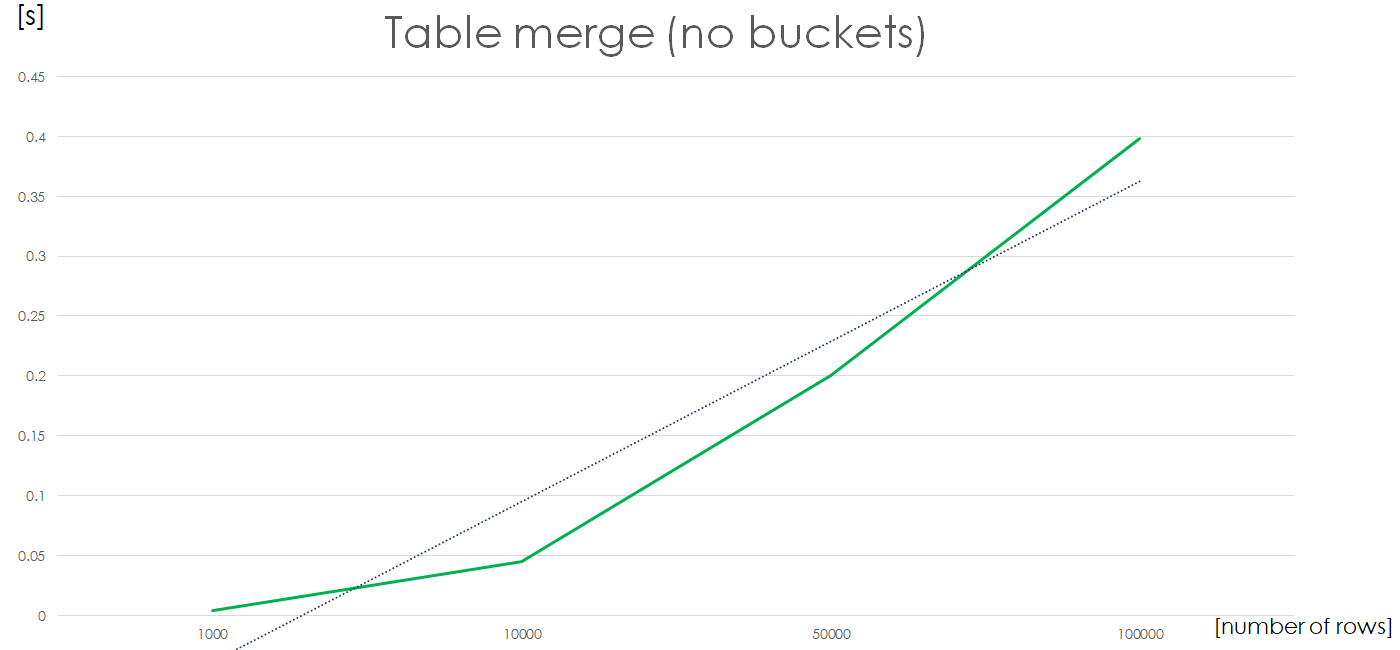
Now the complexity chart looks a lot better. A 2x increase in number of rows in a file results in ~2x increase in calculation time i.e. we have a linear complexity for a file with no XML columns.
Parallel Calculations
Since the number and values of XML columns remain unknown, it’s not possible to further optimize it sequentially as it requires traversing each cell. However, since we are able to link buckets with rest of rows in the DataTable on ID, we can use a parallel calculation.
The issue is that DataTable in C# is thread-safe only for reading, writing to it yields random errors. From the available data structures I picked ConcurrentDictionary as it offers all we need for this task and has a good performance plus offers thread safety.
if (bucketColumnsPositions.Count > 0)
{
Parallel.For(0, source.Rows.Count, (i, row) => {
var xmlBucket = new RateBucketsOverride();
foreach (var idx in bucketColumnsPositions)
{
var cellValue = source.Rows[i].ItemArray[idx].ToString();
if (!string.IsNullOrWhiteSpace(cellValue))
{
xmlBucket.BucketOverrides.Add(
new BucketOverride
{
BucketDescription = source.Columns[idx].ColumnName,
BucketOverrideValue = cellValue
});
}
}
if (xmlBucket.BucketOverrides.Count > 0)
xmlBuckets.TryAdd(i, ToXml(xmlBucket));
});
foreach (var bucket in xmlBuckets)
{
source.Rows[bucket.Key][_dataSchemaService.ColumnXmlBucket] = bucket.Value;
}
}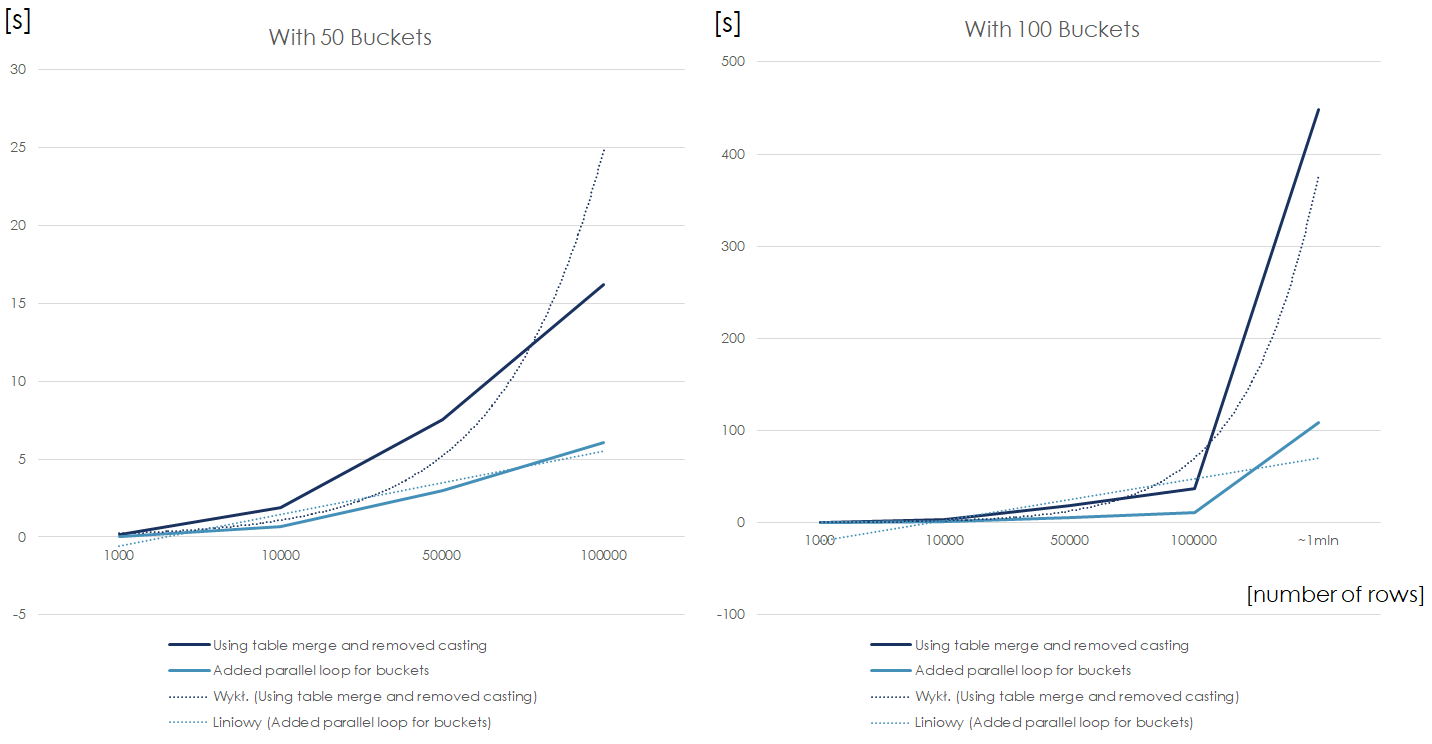
This is a calculation time comparison of the sequential and parallel algorithms using files with 50 and 100 XML columns respectively. We can notice that when the number of rows is drastically higher than number of available threads, the parallel chart breaks the linearity and becomes n (number of rows) * m (number of XML columns above the number of threads).
Thanks to the parallel loops for of XML columns, the growth of calculation time is linear both in terms of number of rows, as well as number of buckets. Precisely, the above is true when number of threads >= number of rows in file, but the reordering service was not a bottleneck anymore.
Bonus: here’s the snapshot from real performance tests. The results for 1,000,000 rows were approximated. In a badly written program, it takes almost two days to reorganize 1mln csv rows for an i7 cpu…